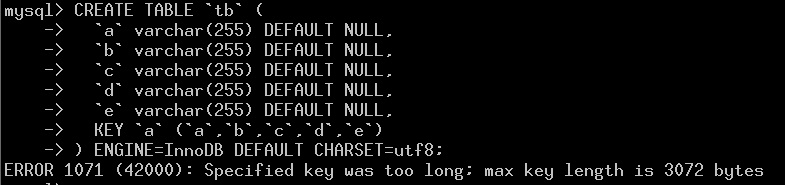
这周阿里集团DBA内部分享时,支付宝的黄忠同学提了一个问题,关于InnoDB索引page 的利用率。
page********利用率
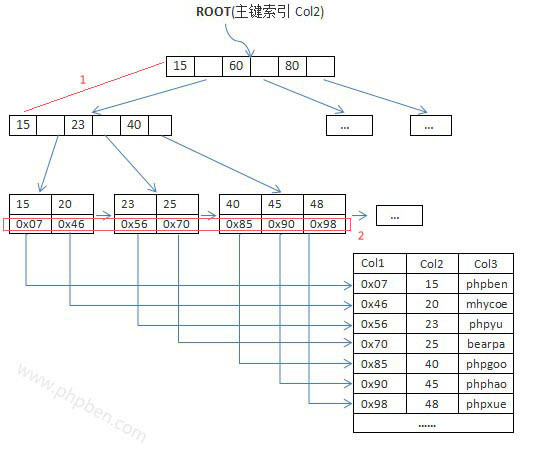
主要是指btee里面每个page的使用被使用的空间大小。我们知道InnoDB默认一个page大小是16k。但实际使用情况不会总用满
我们定义为所有page的总使用字节除以总字节数。
在理论分析之前,我们要先弄个工具,查一下。
实例统计
写了一个简单的工具,读ibd文件上的每个page,算出每个page的实际使用字节,可以得到利用率。
我们找了线上一个库来模拟。表中有1个自增主键和3个非聚簇索引。不影响结论地简化为如下:
CREATE TABLE ctu_factor_risk_99_03 (
seq_id bigint(20) unsigned NOT NULL AUTO_INCREMENT,
a varchar(32) DEFAULT NULL,
b varchar(32) DEFAULT NULL,
c varchar(32) DEFAULT NULL,
KEY a (a),
KEY bc (b,c),
KEY cb (c,b),
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
插入数据中a,b,c均为长度为30字节的随机字符串。
显然主键和其他索引应该分开统计。统计结果发现,主键page利用率71%,其他索引利用率约52%。
简单分析
上面的结果很好理解。因为按照主键递增顺序插入数据,因此主键上数据“紧凑”。 而其他三个索引,则都是随机更新,需要不停地作索引节点分裂。
如何提升磁盘空间利用率
回到最开始的问题。其实我们关心的,是InnoDB为了保存相同的数据,用了多少空间。所以我们的问题变成,存储相同的数据, 如何让占用的磁盘空间更小。
有一个很直观的结论。把这些索引删了重建,必然会减少空间消耗。因为这个操作之后,在新的数据插入之前,这些索引也变成“紧凑的”。
再建了一个与cb相同的索引,再跑,利用率居然高达98%。这个原理大家应该都知道了,只是量化一下而已。
工具附后, 用法 ./ibd_used tb.ibd N1 N2 >/tmp/r 最后几行为各个索引的利用率统计值
http://dinglin.iteye.com/blog/1501933


 ][1]
][1]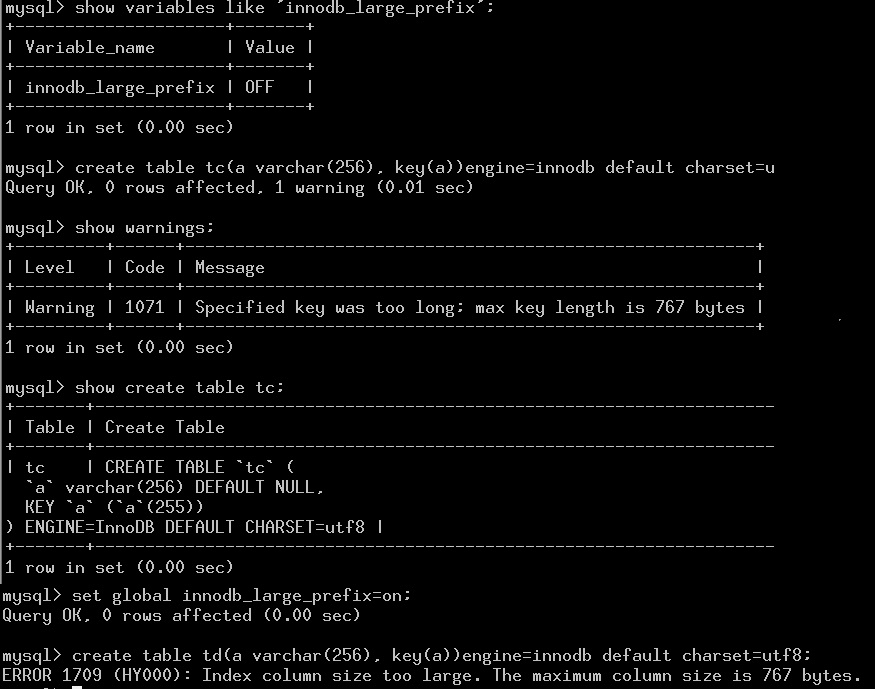 ][2]
][2]

 ]
]
 ][3]
][3]