[译]Go里面的unsafe包详解
unsafe包位置: src/unsafe/unsafe.go
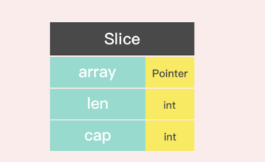
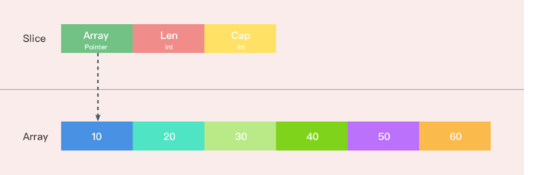
指针类型: ***类型:**普通指针,用于传递对象地址,不能进行指针运算。 **unsafe.Pointer:**通用指针,用于转换不同类型的指针,不能进行指针运算。 **uintptr:**用于指针运算,GC 不把 uintptr 当指针,uintptr 无法持有对象。uintptr 类型的目标会被 GC 回收。
unsafe.Pointer 可以和 普通指针 进行相互转换。
unsafe.Pointer 可以和 uintptr 进行相互转换。
也就是说 unsafe.Pointer 是桥梁,可以让任意类型的指针实现相互转换,也可以将任意类型的指针转换为 uintptr 进行指针运算。
一般使用流程: 第一步:将结构体 -> 通用指针unsafe.Pointer(struct) -> uintptr(通用指针)获取内存段的起始位置start_pos,并记录下来,第二步使用。 第二步:使用start_pos + unsafe.Offsetof(s.b) -> 将地址转为能用指针unsafe.Pointer(new_pos)->转为普通指针np = (*byte)(p)->赋值 *np = 20 第三步:打印结构体,发现内容发生了更改。
推荐:unsafe.Sizeof() 针对不同数据类型的情况
By admin
read more